How I gained access to chef, docker, AWS, and MongoDB instances in a single request

The following article details the successful exploitation of a server sided request forgery vulnerability in Yahoo's small business platform. If you have any questions feel free to tweet me @samwcyo.
Reconnaissance
Whenever I see a directory that looks interesting I'll run a scan on it using dirsearch. To be honest I'm often left disappointed or banned after sending so many requests, but in other circumstances I'll have received a few beautiful 200 OK's in the response.

If you were to proxy all the requests made while loading the site editor one of the directories you'll come in contact with is located at the following:
_/P/COMGR/ys-172540867-9/mtool/goe/_
The output for the scan on this folder showed that a file named "config.json" existed. After checking to see whether it was a false positive, I was greeted with a bunch of endpoints that were either old or inaccessible. One of the endpoints was a proxy from Yahoo to a domain I'd never seen before...
"catalogapi_url": "http://iproxy.store.yahoo.com/store_proxy/proxy.php?url=http://bizapi.store.lumsb.com:4080/catalogapi/v1"
It appeared that this was an old (or potentially internal) file used to proxy to other locations.
After trying to load http://bizapi.store.lumsb.com:4080/catalogapi/v1 chrome threw "ERR_CONNECTION_TIMED_OUT". Based on the response I went ahead and made the assumption it was an internal domain, but decided to run sublist3r on it just in case one of the sub-domains was pointed to something public.
The output was very exciting!
chef.corp.lumsb.com
chef-aws.corp.lumsb.com
docker.corp.lumsb.com
graylog.corp.lumsb.com
graylog01.corp.lumsb.com
mongodb.corp.lumsb.com
mongodb-config01.corp.lumsb.com
mongodb-router01.corp.lumsb.com
mongodb-shard01.corp.lumsb.com
ftps1.store.dc11.lumsb.com
ftps2.store.dc11.lumsb.com
admin1.dom.vip.dc11.lumsb.com
api.catalog.store.vip.dc11.lumsb.com
ftps.store.vip.dc11.lumsb.com
api.order.store.vip.dc11.lumsb.com
api.payment.store.vip.dc11.lumsb.com
webapi.store.vip.dc11.lumsb.com
Sadly all of it was pointing to something internal -- but hey, we're hackers, right?
How do we read from domains on closed networks?
Earlier this year me and another researcher "dawgyg" stole the AWS metadata (and IAM secret access keys) from Luminate by exploiting server side request forgery that took screenshots of a specific page. The issue was awarded and the keys were revoked and removed, but there still existed a screenshot function on the same sub-domain discovered after inspect-elementing a random image inside the Luminate control panel.
https://webshots.luminate.com/img/imc-prod/desktop/tn/vbid-5b84fba5-oofpxx3f
If you were to load the endpoint listed above into a web browser the contents of an image would be returned. This same endpoint was used to take screenshots of different websites under construction in order to show a preview of the landing page. An example control panel with screenshots captured is displayed below...
There was no immediate connection between the website and the screenshot. I'd been pondering the issue for maybe thirty minutes (trying to inject CRLF characters, attempt directory traversal, etc.) when I realized that "vbid" was also a parameter passed when attempting to preview a website via editor.luminate.com...
https://editor.luminate.com/viewer/vbid-63d9ad0f782a4a11bc2cd0f5fbc53e87/vbid-a147c-eauyruotdg
The reason I noticed the correspondence was because of a text file I keep open of interesting IDs, endpoints, and unique strings present in each target.
In addition to all of these discoveries I found out that each element inside of the site editor has a specific "stripe_id". This unique identifier happens to follow the same format as the vbid and can also be previewed within the luminate viewer listed above, but most importantly can be loaded using the screenshot function via...
https://webshots.luminate.com/img/imc-prod/desktop/tn/<< insert unique stripe ID to be previewed >>
Now what?
Awesome! We can take screenshots of our website! But wait... how do we exploit this?
During my five minute break (pomodoro technique - shout out to Jobert) I had developed a really rough hypothetical attack on the system in place. If I was able to find an XSS vulnerability within the site editor then I could then embed an iframe or script that the server would load and use to send a request. It looked something like this...
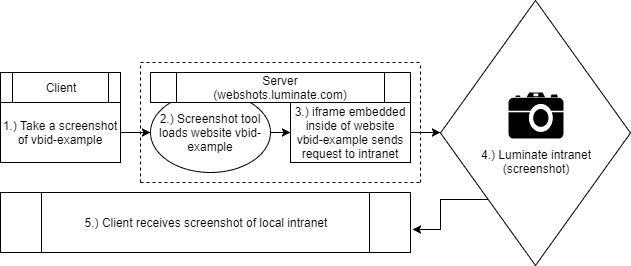
The idea was very simple but I had no idea whether or not it would work. Would the server block requests made inside the iframe? Would it fail to redirect? Would it even load the domains? There was a lot of doubt in my mind but I was pretty sure that it would work.
XSS - well that was easy...
Turns out you can just...
- Add a text element to your page
- Modify the text element to have content type "text/html" (yes this is a parameter)
- Insert your payload
I'm almost a hundred percent sure that Yahoo has already been reported of this issue so I decided to briefly mention it on my report versus create a new report for the issue. It has since been fixed.
POST /update_element_content HTTP/1.1
Host: editor.luminate.com
Accept: application/json, text/javascript, */*; q=0.01
Accept-Language: en-US,en;q=0.5
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
X-Requested-With: XMLHttpRequest
Content-Length: 580
element_id=vbid-4ec19994-ei0hjxj4&parent_id=vbid-4ec19994-kvrvedax&prop_name=TEXT&prop_value=**<iframe src="">**&stripe_id=**vbid-4ec19994-baocz6kq**&old_prop_name=TEXT&old_prop_value=Lorem+ipsum+dolor+sit+amet%2C+consectetur+adipiscing+elit.+Sed+malesuada+faucibus+ex+nec+ultricies.+Donec+mattis+egestas+nisi+non+pretium.+Suspendisse+nec+eros+ut+erat+facilisis+maximus.%3Cbr%3E&root_id=vbid-4ec19994-tgnbo9kq
Lets pull some metadata!
After stringing everything together and creating my new element with the iframe payload everything was ready to be tested. The goal was to have the screenshot tool capture a picture of the AWS metadata IP (http://169.254.169.254/) and fetch the content hosted there.
The first time I tried this it returned nothing but white and a black border. It seemed that everything was loading properly, but the iframe was failing to load. After trying this a second time with Google and having it succeed I realized that the issue was either (1) they blocked the AWS metadata IP after me and Tommy pwned it or (2) they removed any mention of the AWS metadata IP when previewing websites. The first one was much more likely, but just in case I decided to use bitly.com.
The result of iframing the bit.ly address?

It's probably hard to tell because of how scaled down the image is but detailed are the results are from the AWS metadata landing page. Success!
Summary
After verifying that I could in fact fetch the AWS meta data I stopped all testing an went ahead and reported the issue. When it comes to bug bounties it's best not to overstay your welcome and definitely better to avoid potential conflict with regards to pivoting. Something that I did with this report (and I'd recommend following the same steps on any other report similar) is simply comment on the report something like "by the way this is probably capable of hitting all of these internal domains. I didn't try it myself because I felt that it could've been observed maliciously".
This allows the response team to identify the root cause, check the impact, then fix the issue without worrying any sensitive information had been leaked. It's always better to build a trusting relationship than cause nervous break downs by hinting at the fact you probably saw live customer information.
Timeline
- July 31st - Issue reported
- July 31st - Report triaged
- August 4th - SSRF fixed
- August 7th - XSS fixed
- August 8th - Pending bounty